Success Run Testing
The whole concept of life durability testing is of such importance to modern industry that we felt it necessary to publish our ideas in this website in order that interested people would have it available as a reference and reminder that it's imperative that everyone engaged in life testing could improve his testing program by avoiding the wasteful practice of running success run tests based on outmoded classical binomial probabilities.
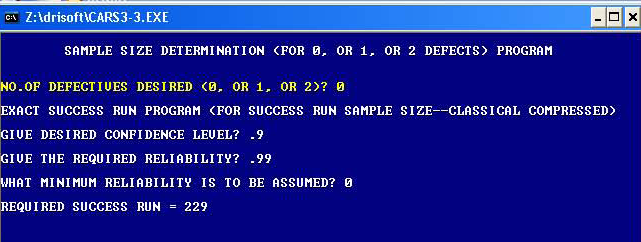
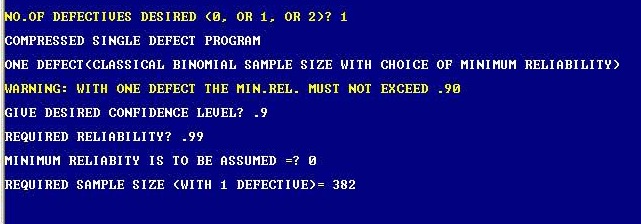
For example, suppose there is a situation in which a Reliability of 99% is being demanded with 90% Confidence to a required life under specific operating condition such as survival to 2,000 Hours (bogey) for an engine. How many consecutive successes are required for these engines? What about when one of the test engines in the sample was defective (i.e., did not last 2,000 Hours), how many more engines must be tested? According to the classical Binomial Probability Theory, it demands that we test 229 such engines to bogey without a single failure and 382 engines with only one defective allowed. It can be seen that the classical approach is totally impractical for such attribute testing programs.
Let's Use Some Common Sense!
If I'm going to sell 100 engines, why should I tested 229 engines (all successes) to a bogey just to be convinced of 99% reliability with 90% confidence? What a waste! Even testing 100 of them is asking too much. I don't want to produce 200 (to allow 100 to be tested) when I'm going to sell only 100. It makes much more sense to test half a dozen all the way to failure. Then I'll have some idea how good the engines are.
What we need is a clear headed approach which really tests an item long enough to make it actually fail. Then we'll know how much it can take.
Conclusion
Success run testing without product verification by actual times to failure requires too large a sample size in order to arrive at its true and verified reliability. If we stop with nothing but successes to a bogey we still won't know how much better it might be.
RECOMMENDATION: Run some items to actual failure so that you can construct a Weibull plot, or an Entropy plot with confidence bands. Success Run Testing for High Reliabilities is a Big Waste.
To the honest observer it is quite obvious that the classical approach to success run testing to a bogey (and attribute testing in general) is plagued with a plethora of opinions resulting in much argumentation and confusion. It is high time for modern industry to knuckle down to business and do some serious research about the question of permissible assumptions regarding the prior probabilities used in the reliability evaluations from attribute tests.
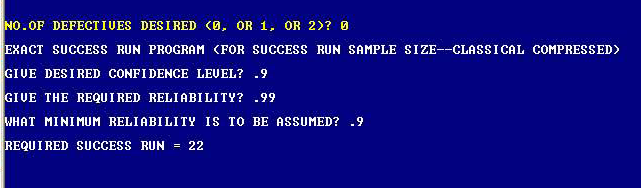
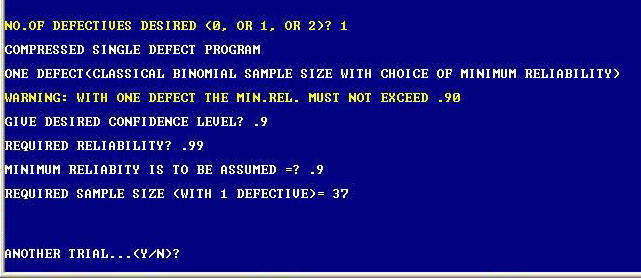
Our CARS3A (Attribute Reliability Tool Box)) software can help you solve this type of problem with sensible sample size. This software quickly tells us the appropriate sample size required for 0, 1, or 2 defectives when we specify the desired values of confidence and reliability, and the assumed minimum reliability with proper restrictions to reflect the reality of any situation involving one or two defectives.
The Sample Size Formulas (Statistical Bulletin Volume 5 Bulletin 3)